Plan · Analyze · Explore
![]()
Installation
Install from CRAN:
install.packages("multitool")You can install the development version of multitool from GitHub with:
# install.packages("devtools")
devtools::install_github("ethan-young/multitool")Motivation
The goal of multitool is to provide a set of tools for designing and running multiverse-style analyses. I designed it to help users create an incremental workflow for slowly building up, keeping track of, and unpacking multiverse analyses and results.
Beyond Multiverse
I designed multitool to do multiverse analysis but its really just a tool for exploration.
In any new field, area, or project, there is a lot of uncertainty about which data analysis decisions to make. Clear research questions and criteria help reduce uncertainty about how to answer them but they never fully reduce them. multitool helps organize and systematically explore different options. That’s really it.
Design
I designed multitool to help users take a single use case (e.g., a single analysis pipeline) and expand it into a workflow to include alternative versions of the same analysis.
For example, imagine you would like to take some data, remove outliers, transform variables, run a linear model, do a post-hoc analysis, and plot the results. multitool can take theses tasks and transform them into a blueprint, which provides instructions for running your analysis pipeline.
The functions were designed to play nice with the tidyverse and require using the base R pipe |>. This makes it easy to quickly convert a single analysis into a multiverse analysis.
Basic components
My vision of a multitool workflow contains five steps:
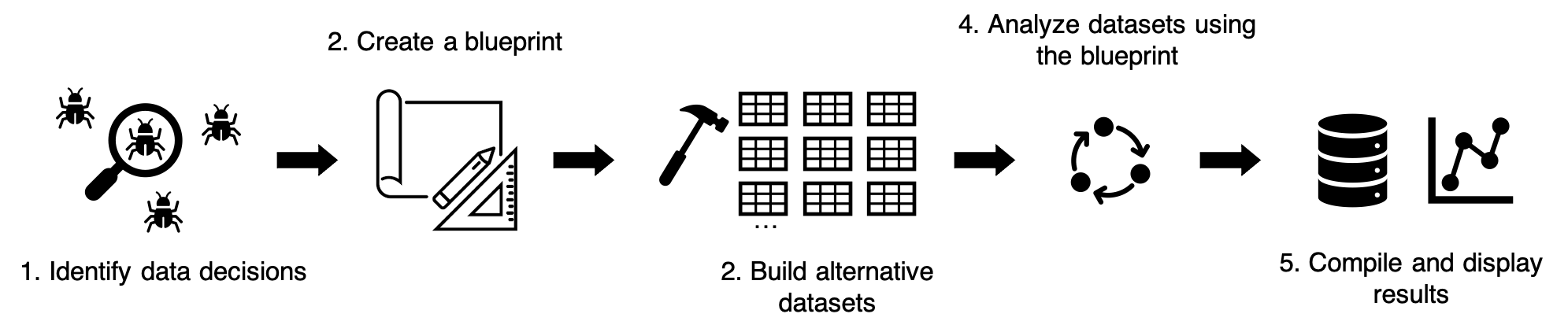
multitool cannot make decisions for you but – once you know your set of data decisions – it can help you create and organize them into the workflow above.
A defining feature of multitool is that it saves your code. This allows the user to grab the code that produces a result and inspect it for accuracy, errors, or simply for peace of mind. By quickly grabbing code, the user can iterate between creating their blueprint and checking that the code works as intended.
multitool allows the user to model data however they’d like. The user is responsible for loading the relevant modeling packages. Regardless of your model choice, multitool will capture your code and build a blueprint with alternative analysis pipelines.
Finally, multiverse analyses were originally intended to look at how model parameters shift as a function of arbitrary data decisions. However, any computation might change depending on how you slice and dice the data. For this reason, I also built functions for computing descriptive, correlation, and reliability analysis alongside a particular modelling pipeline.
Usage
# load packages
library(tidyverse)
library(multitool)
# create some data
the_data <-
data.frame(
id = 1:100,
iv1 = rnorm(100),
iv2 = rnorm(100),
iv3 = rnorm(100),
mod = rnorm(100),
dv1 = rnorm(100),
dv2 = rnorm(100),
include1 = rbinom(100, size = 1, prob = .1),
include2 = sample(1:3, size = 100, replace = TRUE),
include3 = rnorm(100)
)
# create a pipeline blueprint
full_pipeline <-
the_data |>
add_filters(include1 == 0, include2 != 3, include3 > -2.5) |>
add_variables(var_group = "ivs", iv1, iv2, iv3) |>
add_variables(var_group = "dvs", dv1, dv2) |>
add_model("linear model", lm({dvs} ~ {ivs} * mod))
full_pipeline
#> # A tibble: 12 × 6
#> type group code model_coefs_fn model_fit_fn model_standardize_fn
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 filters include1 incl… <NA> <NA> <NA>
#> 2 filters include1 incl… <NA> <NA> <NA>
#> 3 filters include2 incl… <NA> <NA> <NA>
#> 4 filters include2 incl… <NA> <NA> <NA>
#> 5 filters include3 incl… <NA> <NA> <NA>
#> 6 filters include3 incl… <NA> <NA> <NA>
#> 7 variables ivs iv1 <NA> <NA> <NA>
#> 8 variables ivs iv2 <NA> <NA> <NA>
#> 9 variables ivs iv3 <NA> <NA> <NA>
#> 10 variables dvs dv1 <NA> <NA> <NA>
#> 11 variables dvs dv2 <NA> <NA> <NA>
#> 12 models linear model lm({… parameters::p… performance… parameters::standar…
# Expand your blueprint into a grid
expanded_pipeline <- expand_decisions(full_pipeline)
expanded_pipeline
#> # A tibble: 48 × 4
#> decision variables filters models
#> <dbl> <list> <list> <list>
#> 1 1 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 2 2 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 3 3 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 4 4 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 5 5 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 6 6 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 7 7 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 8 8 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 9 9 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> 10 10 <tibble [1 × 2]> <tibble [1 × 3]> <tibble [1 × 5]>
#> # ℹ 38 more rows
# Run the blueprint
multiverse_results <- analyze_grid(expanded_pipeline)
multiverse_results
#> # A tibble: 48 × 5
#> decision specifications model_fitted pipeline_code timing_logs
#> <dbl> <list> <list> <list> <list>
#> 1 1 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 2 2 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 3 3 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 4 4 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 5 5 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 6 6 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 7 7 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 8 8 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 9 9 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> 10 10 <tibble [1 × 3]> <tibble [1 × 5]> <tibble [1 × 4]> <tibble [1 × 4]>
#> # ℹ 38 more rows
# Unpack model coefficients
multiverse_results |>
unpack_model_parameters()
#> # A tibble: 192 × 21
#> decision ivs dvs include1 include2 include3 model_meta model_function
#> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 2 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 3 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 4 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 5 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 6 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 7 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 8 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 9 3 iv2 dv1 include1 ==… include… include… linear mo… lm
#> 10 3 iv2 dv1 include1 ==… include… include… linear mo… lm
#> # ℹ 182 more rows
#> # ℹ 13 more variables: parameter <chr>, coefficient <dbl>, se <dbl>, ci <dbl>,
#> # ci_low <dbl>, ci_high <dbl>, t <dbl>, df_error <int>, p <dbl>,
#> # std_coefficient <dbl>, std_ci <dbl>, std_ci_low <dbl>, std_ci_high <dbl>
# Unpack model fit statistics
multiverse_results |>
unpack_model_parameters()
#> # A tibble: 192 × 21
#> decision ivs dvs include1 include2 include3 model_meta model_function
#> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 2 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 3 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 4 1 iv1 dv1 include1 ==… include… include… linear mo… lm
#> 5 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 6 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 7 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 8 2 iv1 dv2 include1 ==… include… include… linear mo… lm
#> 9 3 iv2 dv1 include1 ==… include… include… linear mo… lm
#> 10 3 iv2 dv1 include1 ==… include… include… linear mo… lm
#> # ℹ 182 more rows
#> # ℹ 13 more variables: parameter <chr>, coefficient <dbl>, se <dbl>, ci <dbl>,
#> # ci_low <dbl>, ci_high <dbl>, t <dbl>, df_error <int>, p <dbl>,
#> # std_coefficient <dbl>, std_ci <dbl>, std_ci_low <dbl>, std_ci_high <dbl>
# Summarize model coefficients
multiverse_results |>
unpack_model_parameters() |>
group_by(parameter) |>
condense(coefficient, list(mean = mean, median = median, sd = sd))
#> # A tibble: 8 × 5
#> parameter coefficient_mean coefficient_median coefficient_sd coefficient_list
#> <chr> <dbl> <dbl> <dbl> <list>
#> 1 (Intercep… -0.0396 -0.0298 0.0812 <dbl [48]>
#> 2 iv1 0.103 0.100 0.140 <dbl [16]>
#> 3 iv1:mod -0.0304 -0.0262 0.178 <dbl [16]>
#> 4 iv2 0.0485 0.0519 0.0197 <dbl [16]>
#> 5 iv2:mod -0.175 -0.157 0.0720 <dbl [16]>
#> 6 iv3 0.149 0.147 0.115 <dbl [16]>
#> 7 iv3:mod 0.142 0.110 0.136 <dbl [16]>
#> 8 mod 0.00364 0.0163 0.0502 <dbl [48]>
# Summarize fit statistics
multiverse_results |>
unpack_model_performance() |>
condense(r2, list(mean = mean, sd = sd))
#> # A tibble: 1 × 3
#> r2_mean r2_sd r2_list
#> <dbl> <dbl> <list>
#> 1 0.0347 0.0305 <dbl [48]>